



How much time are you currently spending researching and vetting vulnerability disclosures? In the current landscape, it seems that many organizations are forced to spend more time on vulnerability assessment than on the actual vulnerability management. Backlogs continue to grow, and it can be hard to prioritize. In an environment where one missed vulnerability can lead to a data breach, you need to know everything you can, as fast as you can.
To effectively make risk-based decisions, organizations require the most accurate, detailed and timely information. Unfortunately, the data that is publicly available is often none of those things. CVE failed to report 29% of the disclosed vulnerabilities aggregated by Flashpoint last year, increasing the total number of vulnerabilities missing CVE IDs to over 80,000. That number is now over 86,000.
That kind of gap is hard to justify to auditors and management. But even if your team isn’t basing their risk decisions directly from CVE/NVD entries, could you say the same for your current Vulnerability Intelligence (VI)?
Where does your data come from?

A poorly kept secret in the security industry is that many security tools almost exclusively base their data and signatures on CVE/NVD entries. So even though what you see and use on a daily basis doesn’t look like CVE, chances are it is heavily based on CVE, or is even a direct copy.
This is most likely the reason as to why your team is often forced to search for vital information such as the status of an exploit. Even where such critical detail is available, it is not always accurate or timely. Unfortunately, it will most likely stay that way as many databases are treated as static entities.
This is a major problem with the typical “one and done” approach that CVE/NVD and other vulnerability databases typically adopt. The vast majority of vulnerability entries are treated like an episode of “The First 48”, where the providers move on to the next thing after disclosing. Using this approach negatively impacts the consumer as vital information such as the availability of a patch, exploit location and exploit availability doesn’t get included once that data is released after the disclosure.
Databases should be a living entity
Flashpoint operates under the belief that vulnerability databases need to be considered living entities. This is because like the times, vulnerabilities are always a-changin’. The disclosure date is not the sole determinant of whether a vulnerability requires action. What really matters is whether new information comes to light that offers more context and/or facilitates remediation. By following this ‘living database’ mentality we are able to better fast-track remediation for our clients, enabling them to spend less time performing research tasks and more time managing and mitigating.
A living database provides value by helping users to:
1. Validate
If your organization is paying for a VI service, it seems counterintuitive if you have to validate the majority of entries. Isn’t VI supposed to make life easier? Sadly, this is a commonplace problem that many security and vulnerability management teams face.
Security teams are often flooded with vulnerabilities affecting major applications like Windows, or are forced to immediately address unexpected situations like the SPECTRE/Meltdown vulnerabilities. Oftentimes the initial disclosure information lacks the level of detail needed to actually prioritize remediation, resulting in teams spending many hours searching for actionable details.
However, that’s the case if organizations rely on a static data source. A proactive approach allows us to find those details for you as well as provide up-to-date references and more accurate CVSS scores than what is publicly available.You can’t move to the next step of prioritizing vulnerabilities if you don’t have all the details, and sometimes we end up finding vulnerability entries that just don’t make sense. For those using CVE/NVD or tools that repurpose that data, you may have occasionally stumbled across some baffling entries too.
Microsoft Defender remote code execution vulnerability
Speaking of vulnerabilities that don’t make sense, consider CVE-2021-1647:
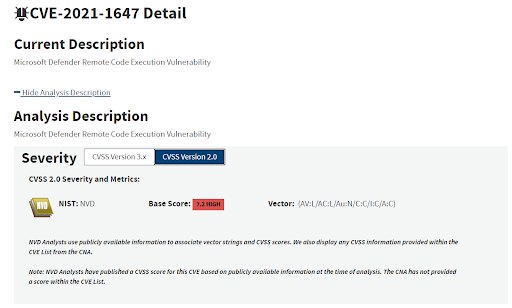
When it comes to serious vulnerabilities, CVE-2021-1647 checks all the boxes. It has a public exploit, has been reported as being actively exploited in the wild, affects a wide range of commonly used products, has low access complexity, and potential to inspire future attacks.
But despite the advisory and being explicitly described as allowing remote code execution, the vendor scored this vulnerability with a local attack vector and NVD blindly copied their score. Something doesn’t add up.
If something doesn’t make sense our research team sets out to find the answers. We quickly reached out to the Microsoft Security Response Center for clarification, added all relevant references, and added technical information to notify our users. We also rescored the vulnerability based on all the newly known details, updating the CVSS score from 7.2 to 10.0.
A simple mistake in labeling vulnerabilities can have serious consequences. This is why treating vulnerability databases as a living entity is essential in providing the most value to its end users. You may want to make sure that this vulnerability didn’t get relegated to a backlog.
2. Prioritize
Over 23,000 vulnerabilities were disclosed in 2020. With disclosure numbers like this, how are organizations supposed to handle such an incredible volume? If your end goal is remediation, you need to be able to effectively prioritize which vulnerabilities get top priority. For threat intelligence and monitoring teams, that may mean remotely exploitable vulnerabilities are on top of the list. For the managers that direct these teams, they may place more or additional emphasis on the availability of a public exploit.
Regardless, making truly risk-based decisions in a timely fashion could be incredibly difficult as most VI platforms don’t provide exploit status. CVE/NVD doesn’t have a reliable method for exploit location other than mining NVD’s CVSS scores, meaning that tools copying that data likely won’t have it either.
It is important to have patch information, exploit location, and exploit availability. With all three pieces of information, an organization better focus on the most critical vulnerabilities.
“Old” vulnerabilities can still be a risk
In many cases, those important details often come after the initial disclosure date. The disclosure date is not, and should not be the sole determinant of whether a vulnerability requires action. Things change all the time within the vulnerability disclosure landscape and organizations need to be completely aware.
For some vulnerabilities like POODLE, our research team has refined its details over 1,200 times. That’s a ton of data, but the good news is that all of it is already indexed for display in our portal or formatted in JSON or XML via API so that it is easy for organizations to consume and automate for remediation. A living database approach ensures that our researchers are constantly updating VulnDB entries for the following:
- Adding caveats and restrictions for exploitation
- Updating with additional technical details released after-the-fact or from third-party analysis
- Updates with solution information
- Adding additional products that are impacted
- Changing the status of the exploit or adding details about it being used in malware campaigns
- Revising the CVSS scores based on new technical details
- Flagging it as “not a vulnerability” if it is determined to be incorrect
The goal is to provide organizations with the most up-to-date and actionable VI so that organizations don’t have to waste time or resources. You can’t achieve that if your database is static.
Down the vulnerability rabbit hole
From time-to-time, you may have read Flashpoint articles that describe “rabbit hole” situations during our vulnerability research. The “rabbit hole”, of course, refers to an opening scene in Lewis Carroll’s iconic 1865 book, “Alice’s Adventures in Wonderland”, where Alice literally falls down a hole after the White Rabbit, transporting her to Wonderland. 150 years later, the term might be used to describe spending a lot of time researching a topic on the Internet.
Falling short of expectations
A vulnerability rabbit hole means that we spent an exorbitant amount of time trying to figure out details for a vulnerability. Hopefully you are already asking yourself the same question we always do, “why should we have to do that?” This is typically the result of a vulnerability disclosure that fell short, in our opinion, either by not providing enough information to make it actionable or by giving conflicting or ambiguous information.
In some cases, we go down these rabbit holes trying to figure out which vulnerability the vendor, researcher, or client is even talking about, just so that we can match it against a known disclosure. Again, we hope you are now asking the fair question “That is ridiculous, why didn’t they just provide a clean cross reference?” If only it could be so simple.
This article will provide one such example of where several elements of vulnerability communication have fallen short. We’ve included a timeline of our rabbit hole adventure at the end, to remind everyone that timelines related to vulnerability disclosures are a big help.
Down the rabbit hole
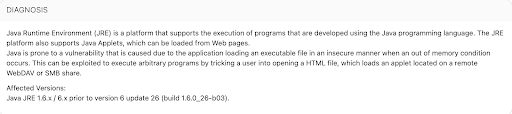
In January, a customer asked us which VulnDB ID is associated with Qualys ID 119389, a vague Java vulnerability. Without access to the software and no additional information, we began digging. Google searches were useless, and none of the Qualys plugins could be found online. Later that day, we reached out to Qualys, Oracle, and ZDI since they were involved in the disclosure.
A week passed before we received a reply from Oracle, who told us that the vulnerability in question was “addressed in JDK 7”. However, they didn’t provide any details about the vulnerability, where it originated, or anything that gave us a real sense of risk. We followed-up with them and they confirmed quickly that it was a “Security-In-Depth issue” and as a result, no CVE ID was assigned.
However, a few days later, Qualys Support replied saying that the same vulnerability “is a zero day vulnerability there is a limited information [sic]”. They also provided a cross reference, citing the blog the alert originated from. It went all the way back to July 8, 2011, where Acros Security disclosed an issue titled “Binary Planting Goes ‘Any File Type’”. This link allowed us to check our database to determine we covered it as VulnDB 74330. At that point we were able to start updating our entry with additional details as we followed-up with Qualys on how they were performing the check.
After more research, Qualys confirmed that they were doing a simple check for the version of Java to determine a vulnerable system. Ultimately, we were able to answer our customer’s question with the help of both Oracle and Qualys, despite us not being a direct customer. In this case, the three of us had a mutual customer that had questions. This highlights why Support or PSIRT answering questions related to older disclosures is still very beneficial to everyone.
The timeline
January 19 – Customer inquires about QID 119389
January 19 – Flashpoint contacts Qualys on customer’s behalf
January 19 – Qualys assigns support case #920749
January 19 – Flashpoint contacts Oracle
January 19 – Flashpoint contacts ZDI
January 19 – Flashpoint reaches out to industry colleagues for screenshots of Qualys ID
January 19 – Colleagues come through, provide screenshots but questions remain unanswered
January 26 – Oracle states “addressed in JDK 7”, provides no further details
January 27 – Oracle confirms it “is a Security-In-Depth issue” and that no CVE has been assigned
February 1 – Qualys states “is a zero day vulnerability there is a limited information [sic]” but provides a cross reference
February 1 – Flashpoint asks Qualys how they are detecting it without details and Flashpoint provides additional cross references
February 3 – Flashpoint notifies ZDI that issue has been resolved
February 24 – Qualys says they are still working on details of the check
March 4 – Qualys says detection is based on a version check of Java
All said and done, it took a good amount of time to answer all of the questions and close out the issue. While digging into an issue like this is a bit painful, it achieves positive results.
It would be a disservice to our customers if we accepted every disclosure as they appear. Organizations are having enough trouble dealing with the incredible amount of vulnerability disclosures and we would prefer that our clients start managing vulnerabilities as fast as they can. If that means that we have to take the time to research on their behalf we will gladly do so. After all, isn’t vulnerability intelligence supposed to make your life easier?